
반응형
🔥 리벨리온 NPU 한방 정리 (GPU 엔지니어 기준)


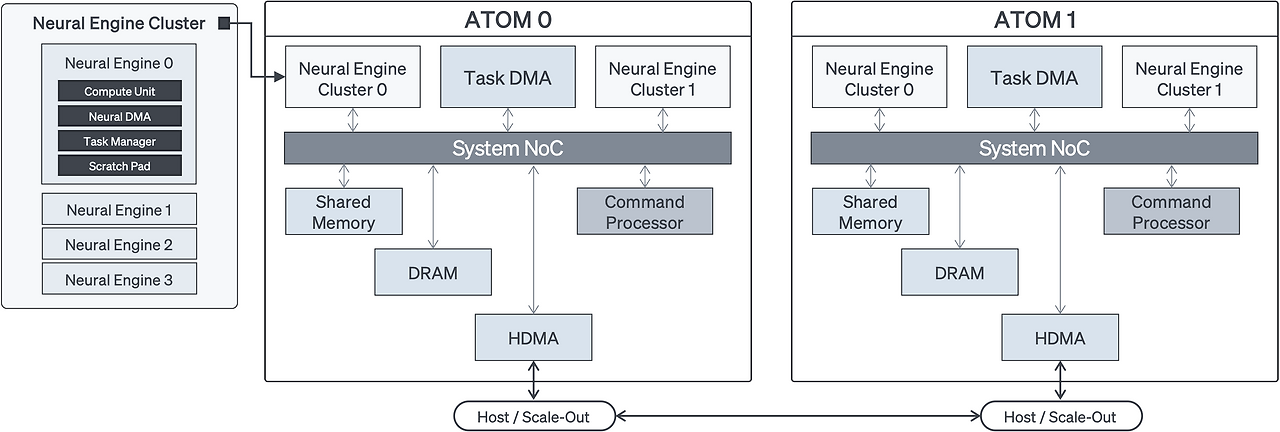
1️⃣ 리벨리온 NPU란?
**Rebellions**에서 만든
👉 AI 전용 반도체 (NPU: Neural Processing Unit)
한줄 요약:
GPU 대신 AI 연산만 집중해서 더 빠르고 효율적으로 처리하는 칩
2️⃣ NPU vs GPU (핵심 차이)
| 구분 | GPU | NPU |
| 목적 | 범용 병렬 연산 | AI 전용 |
| 대표 | NVIDIA H100 | 리벨리온 ATOM |
| 구조 | CUDA 코어 기반 | Tensor/AI 연산 특화 |
| 효율 | 좋음 | 🔥 매우 좋음 |
| 전력 | 높음 | 낮음 |
| 사용처 | 학습 + 추론 | 주로 추론 (Inference) |
👉 핵심 포인트
- GPU = 만능 (학습 + 추론)
- NPU = AI만 잘함 (특히 추론 최적화)
3️⃣ 리벨리온 NPU 종류
🔹 ATOM (대표 제품)
- 금융/데이터센터 추론 특화
- Transformer, NLP 모델 최적화
- CPU 서버에 꽂아서 사용 (PCIe 카드 형태)
👉 느낌:
“GPU 대신 꽂는 AI 추론 전용 카드”
🔹 (차세대) REBEL / AI 서버용 칩
- 데이터센터 확장용
- GPU 대체를 목표로 개발 중
- LLM inference 최적화 방향
4️⃣ 왜 GPU 대신 NPU 쓰냐?
🚀 이유 3가지
1. 전력 효율 (가장 중요)
- GPU: 전기 많이 먹음 💀
- NPU: 같은 성능 대비 전력 ↓↓↓
👉 데이터센터 비용 절감 핵심
2. 추론 성능 특화
- GPT, BERT 같은 모델
- inference latency ↓
👉 “빠르게 답하는 AI 서비스”에 최적
3. 비용 절감
- GPU는 너무 비쌈 (특히 NVIDIA)
- NPU는 특정 작업에서 가격 대비 성능↑
5️⃣ GPU 엔지니어 기준 핵심 이해
💡 구조적으로 보면
- GPU = SIMD + 범용 병렬 처리
- NPU = Tensor 연산만 극단적으로 최적화
👉 쉽게 말하면
GPU = "칼 + 망치 + 드라이버"
NPU = "AI 전용 초고속 드릴"
6️⃣ 언제 NPU 쓰면 좋냐?
👍 추천 케이스
- LLM inference (챗봇 서비스)
- 금융 AI (사기 탐지, 리스크 분석)
- 검색/추천 시스템
- API 기반 AI 서비스
❌ 비추천 케이스
- 모델 학습 (Training)
- CUDA 기반 기존 코드
- 범용 HPC 작업
7️⃣ 실제 현업 관점 (중요🔥)
너 같은 GPU 엔지니어 기준으로 보면:
✔ GPU → 인프라 중심
- Kubernetes + Kubeflow + NCCL
- multi-node training
✔ NPU → 서비스 중심
- inference endpoint
- low latency / high throughput
👉 결론:
GPU는 "학습 인프라"
NPU는 "서비스 최적화 칩"
✅ 최종 정리
- 리벨리온 NPU = AI 추론 특화 반도체
- GPU 대비 전력 효율 + 비용 효율 + latency 우수
- 하지만 학습은 아직 GPU가 압도적
🔥 한줄 핵심
“GPU는 AI를 만드는 장비, NPU는 AI를 서비스하는 장비”
반응형
'[GPUaaS] > GPUmgt' 카테고리의 다른 글
| [🚀 GPU] Fabric Manager란 무엇인가? (1) | 2026.04.26 |
|---|---|
| [🚀 GPU] MLXP vs Run.ai vs Slurm 완전 정리 !! (1) | 2026.04.12 |
| [🚀 GPU] FlashAttention 완벽 가이드 (초보자용) (0) | 2026.04.12 |
| [TFLOPS] Floating Point Operations Per Second !! (0) | 2026.04.10 |
| 🚀[GPU] H100 vs H200 vs B200 vs Vera Rubin 완벽 이해 가이드 (초보자용) (0) | 2026.04.06 |
| 🌐 [WEB Error] 401 / 403 / 500 / 504 완전 정리 (초보자용) (0) | 2026.04.06 |
| [스토리지] TB (테라바이트) vs TiB (테비바이트) !! (0) | 2026.04.02 |
| [GPU] 사용률 평균 계산법 완벽 정리 (일반평균 vs 가중평균) (1) | 2026.04.01 |




댓글