
A business has developed an application that analyzes inventory data by using overnight digital photographs of items on shop shelves. The application is deployed on Amazon EC2 instances behind an Application Load Balancer (ALB) and retrieves photos from an Amazon S3 bucket for metadata processing by worker nodes. A solutions architect must guarantee that worker nodes process each picture.
What actions should the solutions architect take to ensure that this need is met in the MOST cost-effective manner possible?
- A. Send the image metadata from the application directly to a second ALB for the worker nodes that use an Auto Scaling group of EC2 Spot Instances as the target group.
- B. Process the image metadata by sending it directly to EC2 Reserved Instances in an Auto Scaling group. With a dynamic scaling policy, use an Amazon CloudWatch metric for average CPU utilization of the Auto Scaling group as soon as the front-end application obtains the images.
- C. Write messages to Amazon Simple Queue Service (Amazon SQS) when the front-end application obtains an image. Process the images with EC2 On- Demand instances in an Auto Scaling group with instance scale-in protection and a fixed number of instances with periodic health checks.
- D. Write messages to Amazon Simple Queue Service (Amazon SQS) when the application obtains an image. Process the images with EC2 Spot Instances in an Auto Scaling group with instance scale-in protection and a dynamic scaling policy using a custom Amazon CloudWatch metric for the current number of messages in the queue.
한글 번역
한 비즈니스에서 상점 선반에 있는 품목의 야간 디지털 사진을 사용하여 재고 데이터를 분석하는 애플리케이션을 개발했습니다. 애플리케이션은 ALB(Application Load Balancer) 뒤의 Amazon EC2 인스턴스에 배포되고 작업자 노드의 메타데이터 처리를 위해 Amazon S3 버킷에서 사진을 검색합니다. 솔루션 설계자는 작업자 노드가 각 그림을 처리하도록 보장해야 합니다.
솔루션 설계자는 가능한 가장 비용 효율적인 방식으로 이러한 요구 사항을 충족하기 위해 어떤 조치를 취해야 합니까?
- A. 애플리케이션의 이미지 메타데이터를 EC2 스팟 인스턴스의 Auto Scaling 그룹을 대상 그룹으로 사용하는 작업자 노드의 두 번째 ALB로 직접 보냅니다.
- B. Auto Scaling 그룹의 EC2 예약 인스턴스로 직접 전송하여 이미지 메타데이터를 처리합니다. 동적 조정 정책에서는 프런트 엔드 애플리케이션이 이미지를 가져오는 즉시 Auto Scaling 그룹의 평균 CPU 사용률에 대해 Amazon CloudWatch 지표를 사용합니다.
- C. 프런트 엔드 애플리케이션이 이미지를 얻을 때 Amazon Simple Queue Service(Amazon SQS)에 메시지를 씁니다. 인스턴스 축소 보호 기능이 있는 Auto Scaling 그룹의 EC2 온디맨드 인스턴스와 정기적인 상태 확인을 통해 고정된 수의 인스턴스로 이미지를 처리합니다.
- D. 애플리케이션이 이미지를 얻을 때 Amazon Simple Queue Service(Amazon SQS)에 메시지를 씁니다. 대기열의 현재 메시지 수에 대한 사용자 지정 Amazon CloudWatch 지표를 사용하여 인스턴스 축소 보호 및 동적 조정 정책이 있는 Auto Scaling 그룹의 EC2 스팟 인스턴스로 이미지를 처리합니다.
정답
- D. Write messages to Amazon Simple Queue Service (Amazon SQS) when the application obtains an image. Process the images with EC2 Spot Instances in an Auto Scaling group with instance scale-in protection and a dynamic scaling policy using a custom Amazon CloudWatch metric for the current number of messages in the queue.
해설
Amazon SQS 및 Amazon EC2 스팟 인스턴스로 비용 효율적인 대기열 작업자 실행
Amazon Simple Queue Service(SQS)는 고객이 애플리케이션의 복원력을 높이기 위해 모범 사례로 AWS 클라우드에서 분리된 워크로드를 실행하는 데 사용됩니다. 작업자 계층을 사용하여 이미지, 오디오, 문서 등의 백그라운드 처리를 수행하고 웹 계층에서 장기 실행 프로세스를 오프로드할 수 있습니다. 이 블로그 게시물에서는 Amazon SQS와 스팟 인스턴스를 페어링하여 작업자 계층에서 비용 절감을 극대화할 때의 이점과 고객 성공 사례를 다룹니다.
솔루션 개요
Amazon SQS는 고객이 마이크로서비스, 분산 시스템 및 서버리스 애플리케이션을 분리하고 확장할 수 있는 완전관리형 메시지 대기열 서비스입니다. 분리된 애플리케이션과 함께 Amazon SQS를 사용하는 것이 일반적인 모범 사례입니다. Amazon SQS는 프런트엔드 애플리케이션과 데이터 처리를 수행하는 작업자 계층 간의 직접 통신을 분리하여 애플리케이션 복원력을 높입니다. 작업자 노드가 실패하면 해당 노드에서 실행 중이던 작업이 다른 노드가 선택할 수 있도록 Amazon SQS 대기열로 돌아갑니다.
프런트엔드 및 작업자 계층은 모두 온디맨드 인스턴스에 비해 대폭 할인된 가격으로 예비 컴퓨팅 용량을 제공하는 스팟 인스턴스에서 실행할 수 있습니다. 스팟 인스턴스는 AWS 클라우드에서 비용을 최적화하고 동일한 예산으로 애플리케이션의 처리량을 최대 10배까지 확장합니다. 스팟 인스턴스는 EC2에 다시 용량이 필요할 때 2분 알림으로 중단될 수 있습니다. 다양한 내결함성 및 유연한 애플리케이션에 스팟 인스턴스를 사용할 수 있습니다. 여기에는 분석, 컨테이너화된 워크로드, 고성능 컴퓨팅(HPC), 상태 비저장 웹 서버, 렌더링, CI/CD 및 대기열 작업자 노드가 포함될 수 있으며 이는 이 게시물의 초점입니다.
분리된 애플리케이션의 작업자 계층은 일반적으로 내결함성이 있습니다. 따라서 인터럽트 가능한 용량에서 실행하기 위한 주요 후보입니다. 스팟 인스턴스에서 실행되는 Amazon SQS는 더 강력하고 비용 최적화된 애플리케이션을 허용합니다.
애플리케이션에 적합하도록 구성한 여러 인스턴스 유형(예: 여러 가용 영역에서 m4.xlarge, m5.xlarge, c5.xlarge 및 c4.xlarge)이 있는 EC2 Auto Scaling 그룹을 사용하여 작업자를 분산시킬 수 있습니다. 여러 스팟 용량 풀(인스턴스 유형과 가용 영역의 조합)에 걸친 계층의 컴퓨팅 용량. 이렇게 하면 작업자 계층이 대기열에서 메시지를 수집하는 데 필요한 확장을 달성하고 스팟 인스턴스 중단이 발생할 때 해당 확장을 유지하면서 각 가용 영역에서 가장 저렴한 스팟 인스턴스를 선택할 가능성이 높아집니다.
Auto Scaling 그룹의 스팟 인스턴스에 대한 용량 최적화 할당 전략을 선택할 수도 있습니다. 이 전략은 중단 가능성이 낮은 인스턴스를 자동으로 선택하여 스팟 중단으로 인해 작업을 다시 시작할 가능성을 줄입니다. 스팟 인스턴스가 중단되면 Auto Scaling 그룹은 원하는 용량을 달성하기 위해 다른 스팟 용량 풀의 용량을 자동으로 보충합니다. 적절한 할당 전략을 선택하는 방법에 대한 자세한 내용 은 블로그 게시물 " Amazon EC2 스팟 인스턴스를 위한 용량 최적화 할당 전략 소개 "를 참조하십시오.
이 블로그에서는 세 가지 주요 사항에 중점을 둡니다.
- Amazon SQS에서 스팟 인스턴스를 사용하기 위한 모범 사례
- 이러한 구성 요소를 사용하는 고객 사례
- 빠르게 시작하는 데 도움이 되는 예시 솔루션
스팟 인스턴스로 Amazon SQS 적용
Amazon SQS는 메시지 지향 미들웨어를 관리하고 운영하는 복잡성을 제거합니다. Amazon SQS를 사용하면 메시지 손실이나 다른 서비스를 사용할 필요 없이 모든 볼륨의 소프트웨어 구성 요소 간에 메시지를 전송, 저장 및 수신할 수 있습니다. Amazon SQS는 몇 초 만에 대기열을 설정할 수 있는 완전 관리형 서비스입니다. 또한 선호하는 SDK를 사용하여 몇 분 안에 대기열에 쓰기 및 읽기를 시작할 수 있습니다.
다음 예제에서는 Amazon SQS 대기열과 스팟 인스턴스를 실행하는 EC2 Auto Scaling 그룹을 결합하는 AWS 아키텍처를 설명합니다. 아키텍처는 Amazon SQS를 사용하여 웹 계층에서 작업자 계층을 분리하는 데 사용됩니다. 이 예에서는 보호 기능(이 게시물의 뒷부분에서 설명함)을 사용하여 현재 작업을 처리 중인 인스턴스가 Dynamic Scaling 으로 인해 축소 활동이 필요함을 감지할 때 Auto Scaling 그룹에 의해 종료되지 않도록 합니다. 정책.
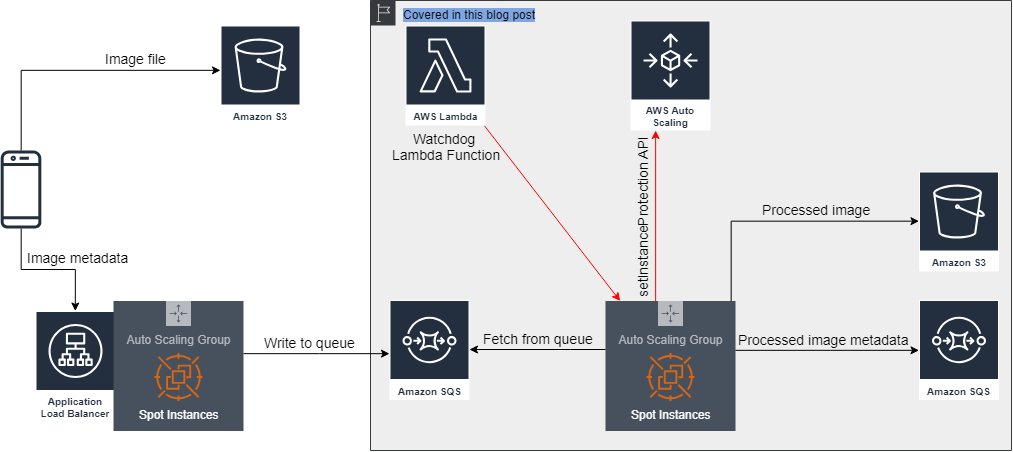
Amazon SQS를 사용하여 웹 계층에서 작업자 계층을 분리하는 데 사용되는 AWS 참조 아키텍처
고객 예: Trax Retail이 Amazon SQS 애플리케이션에서 스팟 인스턴스와 함께 Auto Scaling 그룹을 사용하는 방법
Trax는 아키텍처의 내결함성 특성과 비용 최적화 목적으로 인해 스팟 인스턴스에서만 대기열 작업자 계층을 실행하기로 결정했습니다. 이 회사는 Computer Vision을 사용하여 소매업의 물리적 세계를 디지털화합니다. 그들의 'Trax Factory'는 개별 선반을 소매점 조건에 대한 데이터와 통찰력으로 변환합니다.
비동기식 이벤트 기반 아키텍처를 사용하여 구축된 Trax Factory는 한 서비스가 완료되면 다른 서비스가 활성화되는 마이크로서비스 클러스터입니다. 작업자 계층은 동적 조정 정책이 있는 Auto Scaling 그룹을 사용하여 작업자 계층의 작업자 노드 수를 늘리거나 줄입니다.
다음을 수행하여 동적 조정 정책을 생성할 수 있습니다.
- Amazon CloudWatch 지표 를 관찰하십시오 . Amazon SQS 대기열(ApproximateNumberOfMessagesVisible)의 현재 메시지 수에 대한 지표를 확인하십시오.
- CloudWatch 경보를 생성합니다 . 이 경보는 이전 단계에서 생성한 메트릭을 기반으로 해야 합니다.
- 동적 조정 정책에서 CloudWatch 경보를 사용합니다 . 이 정책을 사용하여 Auto Scaling 그룹의 EC2 인스턴스 수를 늘리거나 줄입니다.
Trax의 경우 대기열에 있는 메시지 수의 높은 변동성으로 인해 SQS API를 호출하고 현재 수를 찾는 서비스를 구축하여 확장하는 데 걸리는 시간을 최소화하기 위해 이 접근 방식을 개선하기로 결정했습니다. CloudWatch에서 5분 지표 새로 고침 간격을 기다리는 대신 대기열에 있는 메시지의 빈도를 높입니다.
Trax는 Amazon EC2 인스턴스의 고유한 탄력성을 활용하여 애플리케이션이 항상 수요를 충족하도록 확장되도록 합니다. 이러한 탄력성은 최종 사용자가 영향을 받지 않거나 SLA(서비스 수준 계약)를 위반하지 않도록 합니다.
Dynamic Scaling Policy를 통해 Auto Scaling 그룹은 대기열의 메시지 수가 감소한 시점을 감지하여 축소 활동을 시작할 수 있습니다. Auto Scaling 그룹은 구성된 종료 정책을 사용하여 종료할 인스턴스를 선택합니다. 그러나 이 정책은 해당 인스턴스가 현재 이미지를 처리하는 동안 Auto Scaling 그룹이 종료할 인스턴스를 선택할 수 있는 위험이 있습니다. 해당 인스턴스의 작업은 손실됩니다(비록 이미지는 결국 대기열에 다시 나타나고 다른 작업자 노드에서 선택하여 처리됨).
이 위험을 줄이기 위해 Auto Scaling 그룹 인스턴스 보호 를 사용할 수 있습니다 . 즉, 인스턴스가 대기열에서 작업을 가져올 때마다 축소로부터 자신을 보호하기 위해 API 호출도 EC2로 보냅니다. Auto Scaling 그룹은 인스턴스가 작업 처리를 완료하고 보호를 제거하기 위해 API를 호출할 때까지 종료할 보호된 작업 인스턴스를 선택하지 않습니다.
스팟 인스턴스 중단 처리
이 인스턴스 보호 솔루션은 축소 활동 중에 작업이 손실되지 않도록 합니다. 그러나 스팟 인스턴스 중단으로 인해 인스턴스가 종료로 표시된 경우 축소로부터 보호하는 기능이 작동하지 않습니다. 이러한 중단은 동일한 용량 풀(가용 영역의 인스턴스 유형 조합)에서 온디맨드 인스턴스에 대한 수요가 증가할 때 발생합니다.
애플리케이션은 스팟 인스턴스 중단의 영향을 최소화할 수 있습니다. 이를 위해 애플리케이션은 2분 간의 중단 알림( 인스턴스의 메타데이터에서 사용 가능 )을 포착하고 대기열에서 작업 가져오기를 중지하도록 지시합니다. 2분이 만료되고 인스턴스가 종료될 때 아직 처리 중인 이미지가 있는 경우 애플리케이션은 프로세스가 완료된 후 대기열에서 메시지를 삭제하지 않습니다. 대신 Amazon SQS 가시성 제한 시간 이 만료 된 후 다른 인스턴스가 선택하고 처리할 수 있도록 메시지가 다시 표시 됩니다.
또는 특정 메시지의 가시성 제한 시간을 0으로 설정하여 스팟 인스턴스 중단 알림을 수신하면 진행 중인 작업을 대기열로 다시 릴리스할 수 있습니다. 이 제한 시간은 잠재적으로 메시지를 처리하는 데 걸리는 총 시간을 줄일 수 있습니다.
솔루션 테스트
현재 대기열 작업자 계층에서 스팟 인스턴스를 사용하지 않는 경우 이 게시물에 설명된 접근 방식을 테스트하는 것이 좋습니다.
이를 위해 AWS CloudFormation 템플릿 을 사용하여 이 게시물에서 언급한 기능을 시연하는 간단한 솔루션을 구축했습니다 . 스택에는 이미지가 Amazon S3 버킷에 업로드된 후 SQS 대기열에 알림을 푸시하는 CloudWatch 트리거가 있는 Amazon Simple Storage Service(S3) 버킷이 포함되어 있습니다. 메시지가 대기열에 있으면 Auto Scaling 그룹의 EC2 인스턴스에서 실행 중인 애플리케이션에서 선택합니다. 그런 다음 이미지가 PDF로 변환되고 활성 처리 작업이 있는 한 인스턴스가 축소되지 않도록 보호됩니다.
솔루션이 작동하는지 확인하려면 CloudFormation 템플릿을 배포하세요. 그런 다음 Amazon S3 버킷에 이미지를 업로드합니다. Auto Scaling Groups 콘솔의 Instances 탭에서 인스턴스 보호 상태를 확인합니다. 보호 상태는 다음 스크린샷에 표시됩니다.

CloudWatch Logs를 사용하여 애플리케이션 로그를 볼 수도 있습니다.
/usr/local/bin/convert-worker.sh: Found 1 messages in https://sqs.us-east-1.amazonaws.com/123456789012/qtest-sqsQueue-1CL0NYLMX64OB
/usr/local/bin/convert-worker.sh: Found work to convert. Details: INPUT=Capture1.PNG, FNAME=capture1, FEXT=png
/usr/local/bin/convert-worker.sh: Running: aws autoscaling set-instance-protection --instance-ids i-0a184c5ae289b2990 --auto-scaling-group-name qtest-autoScalingGroup-QTGZX5N70POL --protected-from-scale-in
/usr/local/bin/convert-worker.sh: Convert done. Copying to S3 and cleaning up
/usr/local/bin/convert-worker.sh: Running: aws s3 cp /tmp/capture1.pdf s3://qtest-s3bucket-18fdpm2j17wxx
/usr/local/bin/convert-worker.sh: Running: aws sqs --output=json delete-message --queue-url https://sqs.us-east-1.amazonaws.com/123456789012/qtest-sqsQueue-1CL0NYLMX64OB --receipt-handle
/usr/local/bin/convert-worker.sh: Running: aws autoscaling set-instance-protection --instance-ids i-0a184c5ae289b2990 --auto-scaling-group-name qtest-autoScalingGroup-QTGZX5N70POL --no-protected-from-scale-in
결론
이 게시물은 비용 최적화 방식으로 내결함성 작업자 계층을 설계하는 데 도움이 됩니다. 대기열 작업자 계층이 내결함성이 있고 기본 제공 Amazon SQS 기능을 사용하는 경우 애플리케이션의 복원력을 높이고 스팟 인스턴스를 활용하여 컴퓨팅 비용을 최대 90% 절약할 수 있습니다.
이 게시물에서는 Amazon SQS 및 스팟 인스턴스를 사용하여 비용 절감을 시작하는 데 도움이 되는 몇 가지 모범 사례를 강조했습니다. 주요 모범 사례는 다음과 같습니다.
- Auto Scaling 그룹을 사용하여 스팟 인스턴스 다양화 및 올바른 스팟 할당 전략 선택
- 작업을 처리하는 동안 축소 활동으로부터 인스턴스 보호
- 인스턴스가 종료되기 전에 애플리케이션이 새 작업에 대한 대기열 폴링을 중지하도록 스팟 중단 알림 사용
이 게시물이 도움이 되었기를 바랍니다. 대기열 작업자 계층에서 스팟 인스턴스를 사용하지 않는 경우 여기에 설명된 접근 방식을 테스트하는 것이 좋습니다.
참조 문서
'[AWS] > AWS SAA EXAMTOPICS' 카테고리의 다른 글
| [AWS][SAA][EXAMTOPICS] Question 335 (0) | 2022.07.15 |
|---|---|
| [AWS][SAA][EXAMTOPICS] Question 334 (0) | 2022.07.15 |
| [AWS][SAA][EXAMTOPICS] Question 333 (0) | 2022.07.15 |
| [AWS][SAA][EXAMTOPICS] Question 332 (0) | 2022.07.15 |
| [AWS][SAA][EXAMTOPICS] Question 330 (0) | 2022.07.14 |
| [AWS][SAA][EXAMTOPICS] Question 329 (0) | 2022.07.14 |
| [AWS][SAA][EXAMTOPICS] Question 328 (0) | 2022.07.14 |
| [AWS][SAA][EXAMTOPICS] Question 327 (0) | 2022.07.14 |


댓글