
## S3 CLI 명령어
https://docs.aws.amazon.com/cli/latest/reference/s3/
s3 — AWS CLI 1.22.64 Command Reference
Note: You are viewing the documentation for an older major version of the AWS CLI (version 1). AWS CLI version 2, the latest major version of AWS CLI, is now stable and recommended for general use. To view this page for the AWS CLI version 2, click here. F
docs.aws.amazon.com
## Gitlab 용 CLI AWS 계정 생성
- gitlabci
- Access type : Programmatic access
- 정책 : S3FullAccess
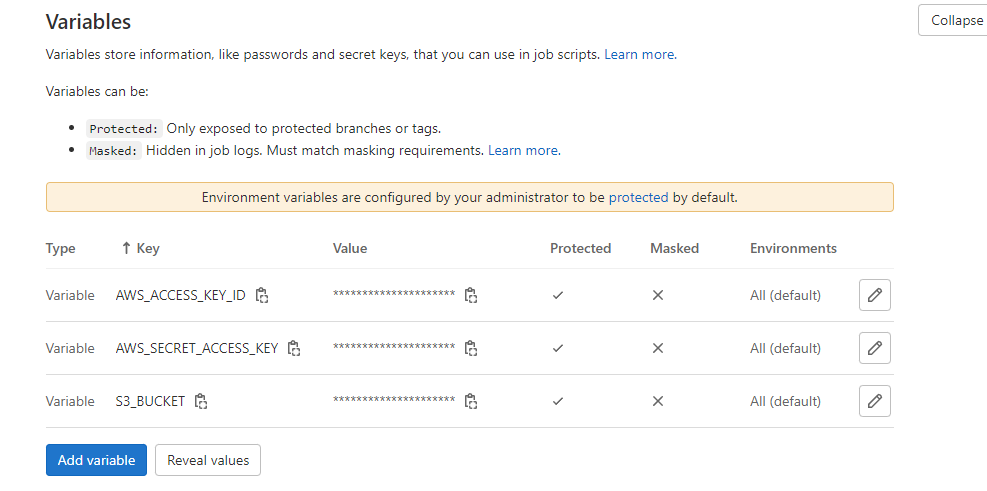
## Gitlab -> Settings -> CICD -> Variables 선언
- AWS_ACCESS_KEY_ID
- AWS_SECRET_ACCESS_KEY
- S3_BUCKET
stages:
# - build
# - test
- deploy
deploy:
stage: deploy
image:
name: amazon/aws-cli
entrypoint: [""]
script:
- aws configure set region ap-northeast-2
#- aws s3 cp ./build/libs/cars-api.jar s3://$S3_BUCKET/cars-api.jar
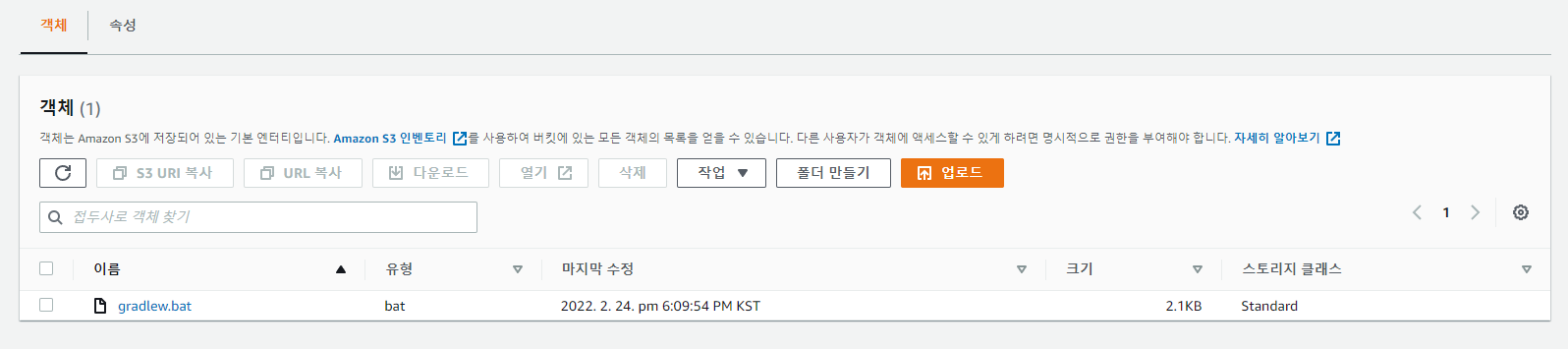
- aws s3 cp ./gradlew.bat s3://$S3_BUCKET/oky/gradlew.bat
#
## S3에 특정 파일 업로드 성공
## .gitlab-ci.yml
stages:
- build
- test
- deploy
build:
stage: build
image: openjdk:12-alpine
script:
- ./gradlew build
artifacts:
paths:
- ./build/libs/
smoke test:
stage: test
image: openjdk:12-alpine
before_script:
- apk --no-cache add curl
script:
- java -jar ./build/libs/cars-api.jar &
- sleep 30
- curl http://localhost:5000/actuator/health | grep "UP"
deploy:
stage: deploy
image:
name: amazon/aws-cli
entrypoint: [""]
script:
- aws configure set region ap-northeast-2
- aws s3 cp ./build/libs/cars-api.jar s3://$S3_BUCKET/cars-api.jar
- aws s3 cp ./gradlew.bat s3://$S3_BUCKET/gradlew.bat
=============================================
The next step in the process would be to modify our pipeline and to upload the artifact from catalepsy
to Adewusi S3 to the S3 market that we have created in order to interact with Amazon Web Services from
Get Lecci, we need to use a tool that AWB provides.
It's the AWB command line interface that AWB Seelie.
Fortunately, there's already a darker image, but it includes the AWB Seelie so we can use it directly
in website.
Let me show you how that works.
So let's go ahead then and deploy stage.
And also the associated job.
I'm going to sign the diploid job to the stage.
And now comes the part that you need to pay attention to.
So I'm going to define an image that I'm going to use, but this time I'm going to set some additional
properties.
Some darker images provide an entry point, this makes it easier when you're running the darker image
to directly interact with that.
But we're seeing this typically causes some problems.
So any images that have an entry point different, even if you don't know what it is, will cause problems.
So for that reason, we need to override the entry point and to say practically it doesn't have an entry
point.
So this is how we can specify no entry point for this image.
Mean the script will have the Seelie available.
This goes something like this can simply say us and because we want to interact with the simple storage
service, S3 can simply say S3.
And then what are you going to do is we're going to copy KTP and we're going to reference the built
folder.
Lipps.
And artifact name will be cast API that jar.
And then we're going to specify the path where we are going to copy this, this will be three.
Slash, slash now going to use the S3 Buckett variable that we have defined previously.
And again, specified the path where they should go and this will still be cast API that DJA.
Because AAUW works with Regents', it is always a good idea to specify which region we are going to
use.
So for that, before wanting to copy command on S3, we're gonna say let's configure.
And I said the region to us is the one, because this is the region that I have been using.
But if you have a different region, you may use that one.
Just to keep things simple, I'm not putting this in a variable, but for your case, it may be a good
idea to put in a variable anything that is variable that may change.
So from this point of view, this is all that we need in order to copy our artifact to S3.
The problem now is that if we simply run this command innumeracy, I will have no idea who we are.
And if we have access to the specific target in this case without providing any credentials, we will
not have access to the market.
So as this stands, this will not work.
So we order to get this to work, we need to generate some credentials to save them and get Lipsky so
that we can provide these credentials to a WCI and then a WCI would be able to copy this file to the
respective bucket.
And trust me, it is quite easy.
Going back to the AWB management console, you have to go to all services and identify I am.
I am stands for identity and access management, practically, this is the service within AWB ensures
that when you're calling a service, you actually have the right credentials.
I'm going to click here on users at the user.
Now, to simply call my user catalepsy.
And I will make sure that this user has programatic access, what this means is practically that we
can use the AWB, CLIA, in this case, wheat, this user.
This is what we want to do.
It's going to go to permissions.
We need to tell us what this user can do.
This case.
We only want to give this user permissions to S3.
So we're going to use policies and policies are predefined rules that can be applied to users.
Of course, you can create your own policies, but just to simplify things, you're going to use an
existing policy.
So in the search field, I'm going to search for S3.
And to make things very, very simple, I'm to select Amazon as three full access, and what this means
is that this user will have access to the S3 bucket, can create and delete and so on, so will have
full access, but only to the S3 service.
You don't see any tanks.
Now, after this overview page, we can go ahead and create that user.
Now, at this final page, it's important that you do not close this yet because we need to save this
information and we know that the user is guilty.
But now what AWB has done has created an excess in a secret access key.
What do we need to do is to copy this information into your lecci variable so that we can use them in
script.
The first variable name that we need to create is called a W.S., underscore excess.
Underscore key.
Underscore a.
And we're going to copy this idea that we have seen from the U.S. consul.
The next variable that will define is called a secret access key with underscores between the words.
I'm going to click here on show, I'm going to copy this secret access key.
And pasted here in this field.
After I'm done, I'm going to see if the variables.
Now we have everything in place in order to start running our pipeline, so I'm going to committees
and let's see how it works.
If you go back to take a look at the pipeline, we see that the deployment succeeded even though it
didn't do a complete deployment, it only copied the artifact to S3.
And just in case you're wondering, how does the Racheli know to use practically the username and password
that we have given?
This is because we have used the convention when we have named our variables.
The way the variables are named isn't arbitrary, isn't something that I have decided.
This is specified in the Serai documentation and I will look for these environmental variables to see
if they exist and if they exist, it will pick them up and use them automatically.
And this is why this deployment now is working.
Going back to the three buckets, if we go now into cars, API deployments or how you have named your
bucket, it will see that it contains now our artifact that we have generated from catalepsy.
If you want to learn more about the WASC ally, commands will link you resources to the official.
A.W. has documentation regarding these tools as a resource to this video.
'[AWS] > GITLAB' 카테고리의 다른 글
| [Git] git 저장소 히스토리 삭제 및 초기화하기 (7) | 2022.08.18 |
|---|---|
| [Git] git 원격 저장소의 파일 삭제하는 방법 (0) | 2022.08.18 |
| [AWS] GIT 과 SVN의 차이점 (0) | 2022.07.19 |
| [AWS][GITLAB] sourcetree란 무엇인가? (0) | 2022.07.18 |
| [AWS] 내부망 GITLAB 설치 (0) | 2022.07.04 |


댓글